If sampling is to be carried out, this section provides a list of information needed to be collect and decisions to be made in order to calculate the number of samples that should be collected.
If census is to be carried out, this section might not be relevant. However, information on the population in 8.1. and 8.2 as well as details on a data collection timeline at 8.8 can be helpful to allocate resources.
8.1 Sampling at the primary sampling unit (PSU) level
The information needed to be collected are:
A) Number of PSU in the population (which should have been determined in section 7)
B) Design prevalence
C) Desired confidence
D) Desired power
E) Sensitivity (Sensitivity at the PSU level equals confidence at the SSU level, if two-stage sampling is used)
F) Specificity
This information will be used in later steps for sample size calculation. In some cases, the sample size is decided a priori, for instance based on a specific budget. If this is the case, then the information in this section would not need to be collected. Then, in step 8.5 (below) you will find a link to tools to explore different sampling options and carry out a power analysis - identify the achievable confidence using the sample size established a priori.
8.2 Sampling at the secondary sampling unit (SSU) level
If one-stage sampling process is applied, then PSU is the only unit to consider (skip this step). For two-stage sampling, the same information should be collected for the SSU level:
A) Number of SSUs in the population (which should have been determined in section 7)
B) Design prevalence
C) Desired confidence
D) Desired power
E) Sensitivity
F) Specificity
8.3 Selection criteria WITHIN the population
In section 3 we discussed criteria to choose the target population. When sampling that target population, however, it is possible that not all animals are reachable (for instance not all units are registered, therefore not all are available in the sampling frame). So here a designer should consider whether, WITHIN the target population, there are any criteria for the selection of animal/units to target which are NOT related to sampling (which is discussed further below).
Criteria for selection could be for instance logistic/convenience (this component focuses on a particular sector of the population because they are easier to sample or more accessible; higher probability of infection; higher probability of showing clinical signs; feasibility of detection (the diagnostic tests available can only be used in animals above a certain age, or non-vaccinated animals); or higher severity of consequences in case of infection, which is the case for instance when surveillance is focused on breeder animals.
8.4 Risk-based allocation
Before establishing the sampling method and details, a surveillance designer should consider the risk characteristics identified in section 1.5. In the RISKSUR framework these risk characteristics are presented back to the user at this stage. If risk-based sampling can be applied to the identified risk strata, this step should be used to define the strata and collect information needed for sample size calculation and allocation. Risk based strategies have been applied to improve the efficiency of surveillance for early detection (particularly for vector borne disease or those with a wildlife reservoir), case detection and demonstrating freedom. It is important when using risk based strategies particularly when doing surveillance for early detection that the possibility of disease occurrence outside the high risk population is considered and additional surveillance (e.g. passive surveillance) is carried out to detect these cases if required.
The link below provides tools that can be used for risk assessment, which would use the information on the distribution of the hazard and the risk in the population in order to determine risk strata for sampling, and estimate some of the information to be recorded for each strata (detailed below).
 RISK ASSESSMENT TOOLS (LINK).
RISK ASSESSMENT TOOLS (LINK).
For each risk stratum defined, the following information should be recorded:
A) Defined due to a higher risk of: Infection, Detection, Consequences, or others? (visit section 1.5 or the Glossary to understand the differences)
B) Any further description - p.e. if based on geographical factors, temporal, etc
C) Percentage of the population
D) Risk ratio
8.5 Sample size calculation
SAMPLE SIZE CALCULATION TOOLS (LINK)
The sample size should be calculated with the information collected so far in this section. When calculating sample sizes the need for exact methods and those that take into account text characteristics and uncertainty should be considered in addition the possibility of including historical information to reduce sample size and cost when carrying out surveillance to demonstrate freedom should be considered. The following details should be recorded:
A) Sample size calculated at PSU level)
B) Sample size calculated (SSU level) - likely to vary per size of the PSU, in which case this may end up being a lookup table, or anther description of the sample size according to the size of the SSU.
C) Expected total number of samples to be collected monthly (this is important to consider laboratory capacity later).
8.6 Sample allocation at the primary level
Once the sample size is known, the next step is to decide how the units will be samples. The diagram below described the sample allocation options, and what information is needed to describe for each option. The surveillance designer should determine which sample allocation method will be used, and describe as many details as needed about the process.
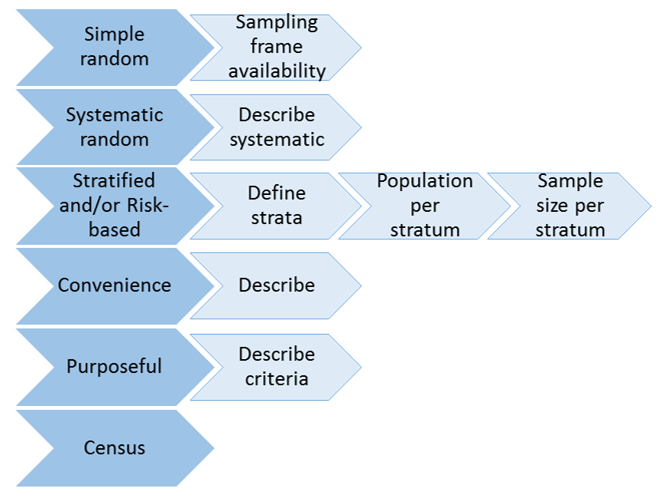
8.7 Sample allocation at the secondary level
The step above should be repeated for sampling at the secondary level, when applicable.
8.8 Sample collection timeline
the study type will have been identified in section 2 (for instance serological survey, continuous data collection, etc); Now that the number of samples is also know, the surveillance designer should detail the collection timeline. For instance, is there a a fixed schedule for visiting the place of collection?
 |  |  |  |  |  |  |  |  |  |
 |  |